In this guide, you will learn how to leverage Neon’s branching feature to create a database for every preview environment. We will use Vercel as an example deployment provider and GitHub actions as the CI/CD tool.
Staging environments and why they are not ideal
Teams often set up a production-like environment, known as “staging”, where they test and validate new features before releasing them. The goal of this pattern is to ensure quality; however, it introduces challenges when you have several developers collaborating on the same project:
- If the staging environment goes down, the entire team cannot preview their changes before deploying to production.
- If a developer wants to preview their changes in isolation, they will prevent other team members from deploying to the staging environment.
- You likely end up with a queue of changes that need to be reviewed, forcing you into doing a big release that includes several changes. The problem with doing a big release is that if something goes wrong unexpectedly, and you’re unsure of the cause, you must undo all of your changes.
Thankfully, a new pattern is becoming increasingly popular: preview environments.
Preview environments: A better way to build software
Rather than having a shared and fixed staging environment where all developers collaborate, you automatically provision a production-like environment for every new code change a developer wants to introduce. In other words, every pull request will have its own isolated, production-like environment.

This enables developers to build new features in parallel without affecting each other. It also makes it possible to do frequent small releases, making it easier to revert changes if something goes wrong.
Many deployment platforms are starting to support this flow out of the box by enabling you to set up an automatic Git integration. This way, you do not have to worry about maintaining and managing the necessary infrastructure for handling this flow.
Working with databases in preview environments
When teams want to set up preview environments for an app that is backed by a database, they typically pick one of the following approaches:
- Setting up a shared database for all previews
- Creating a database for every pull request and seeding it with random data
- Creating a database for every pull request and seeding it with production data
All of these options are not ideal and present their own drawbacks.
Creating a database for every pull request and seeding it with random data means that preview environments will not accurately represent production. So you will not be able to make changes to your production database confidently.
The alternative would be to create a database for every pull request and import a backup of the production database. The problem with this flow is that depending on the size of your database, it can take a long time to deploy a preview environment.
That is why teams often skip the step of creating a database for every preview and just use a shared database. The drawback is that any changes made to that shared database will impact all active previews. So, if a developer’s changes include evolving the database schema, they must notify their team members about this change and potentially prevent them from deploying. Furthermore, if the shared database goes down, no one will be able to create preview environments. This flow is somewhat similar to having a staging environment, but now the database is the bottleneck.
The great news is that you can use Neon’s branching feature to create a production-like database for every preview. This database will contain production data and can be created in seconds.
What is Neon?
Neon is fully managed serverless Postgres. This means you don’t have to pick a size for your database upfront, and it will automatically allocate resources to meet your database’s workload.
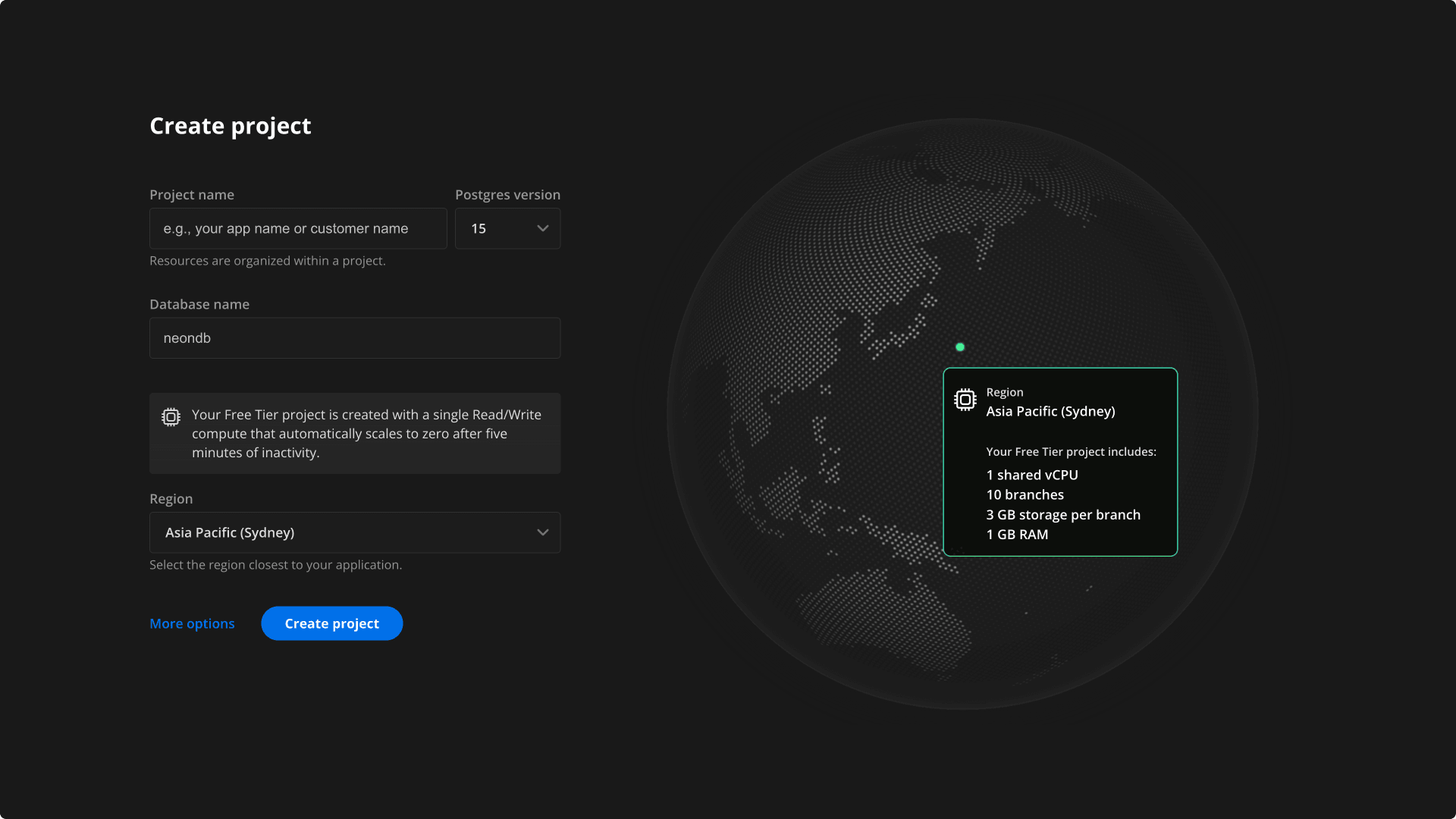
To get started, go ahead and create an account. Next, you will want to create a new project. Choose a Postgres version, pick the region that’s closest to where you want to deploy your app. After you create the project, you will get a connection string that you can use to connect to your database.
Neon’s architecture separates storage and compute. This makes a Neon Postgres instance stateless, which makes it possible to automatically scale compute resources up or down based on demand. To learn more, check out Neon’s architecture.
Neon’s object hierarchy
When you create a project in Neon, a default Postgres cluster is created with a default database called neondb. Within a project’s Postgres cluster, you can have many databases.

This is important to know because it will help you understand how Neon’s branching feature works.
Neon branching
Neon enables you to create copies of your project’s Postgres cluster, where each copy is completely isolated from the other. We call this copying process “branching” and call each copy a “branch”.
The default Postgres cluster that gets created along with a new project is represented by a branch called main.
Neon branches are:
- Isolated: changes made to a branch don’t affect its parent
- Fast to create: creating a branch takes ~1 second, regardless of the size of your database.
- Cost-effective: you’re only billed for unique data across all branches, and they scale to zero when not in use (you can configure this behavior for every branch).
- Ready to use: branches will have the parent branch’s schema and all its data (you can also include data up to a certain point in time)
Creating a branch in the Neon console
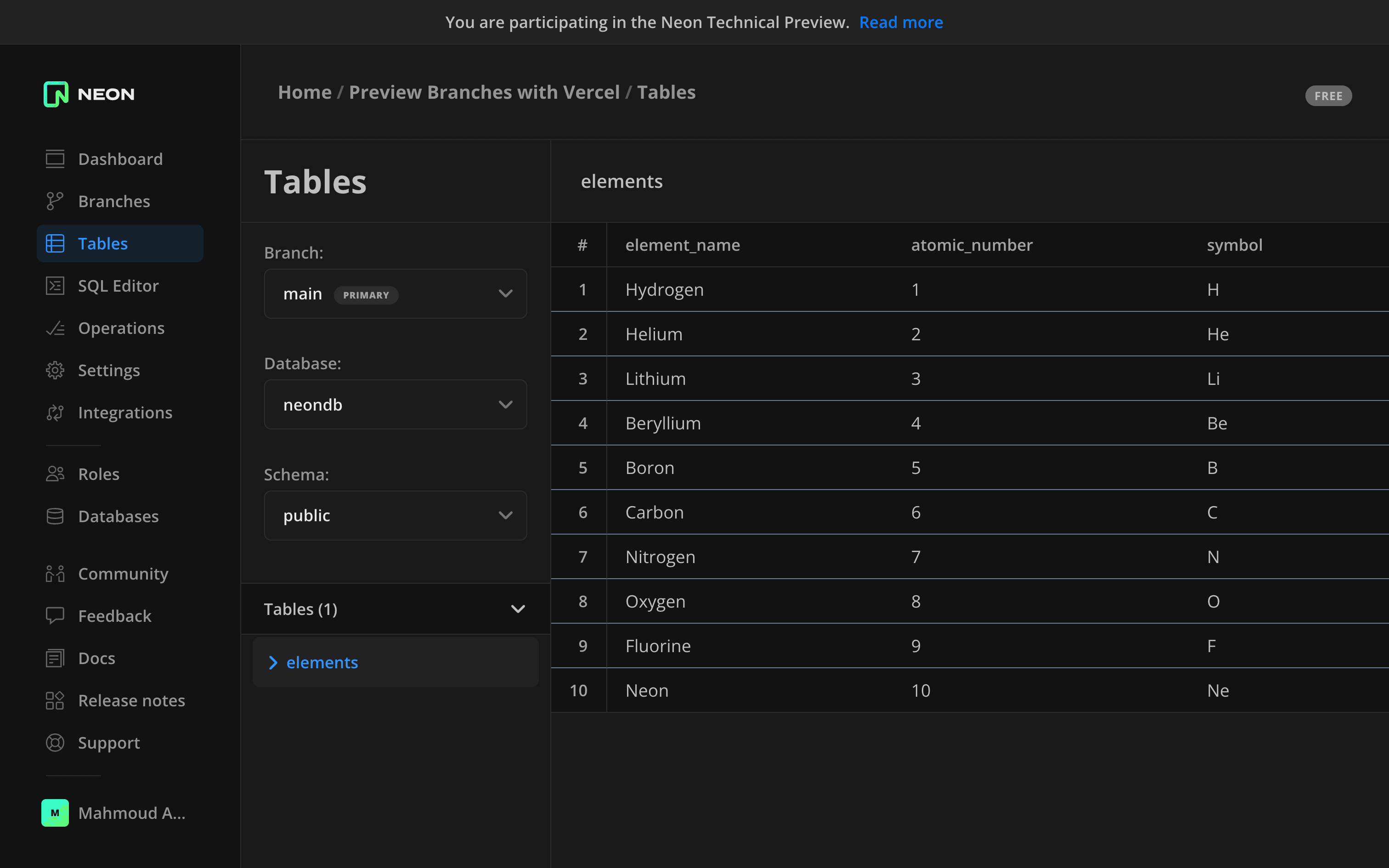
To see branching in action, you will first need to create a new table and add some data to it. Navigate to the SQL Editor and add the following SQL query.
CREATE TABLE elements ( element_name VARCHAR(50), atomic_number INT, symbol VARCHAR(10) );
INSERT INTO elements VALUES ('Hydrogen', 1, 'H'), ('Helium', 2, 'He'), ('Lithium', 3, 'Li'), ('Beryllium', 4, 'Be'), ('Boron', 5, 'B'), ('Carbon', 6, 'C'), ('Nitrogen', 7, 'N'), ('Oxygen', 8, 'O'), ('Fluorine', 9, 'F'), ('Neon', 10, 'Ne');This query creates a new table called elements. The table has three columns: element_name, atomic_number, and symbol. You are then inserting ten elements into that table.
You can check that the data was added by going to the “Tables” page. You will find that you have a table called elements with ten items.
To create a branch, go to the “Branches” page, and click “New Branch”. You will then be redirected to the branch creation page.
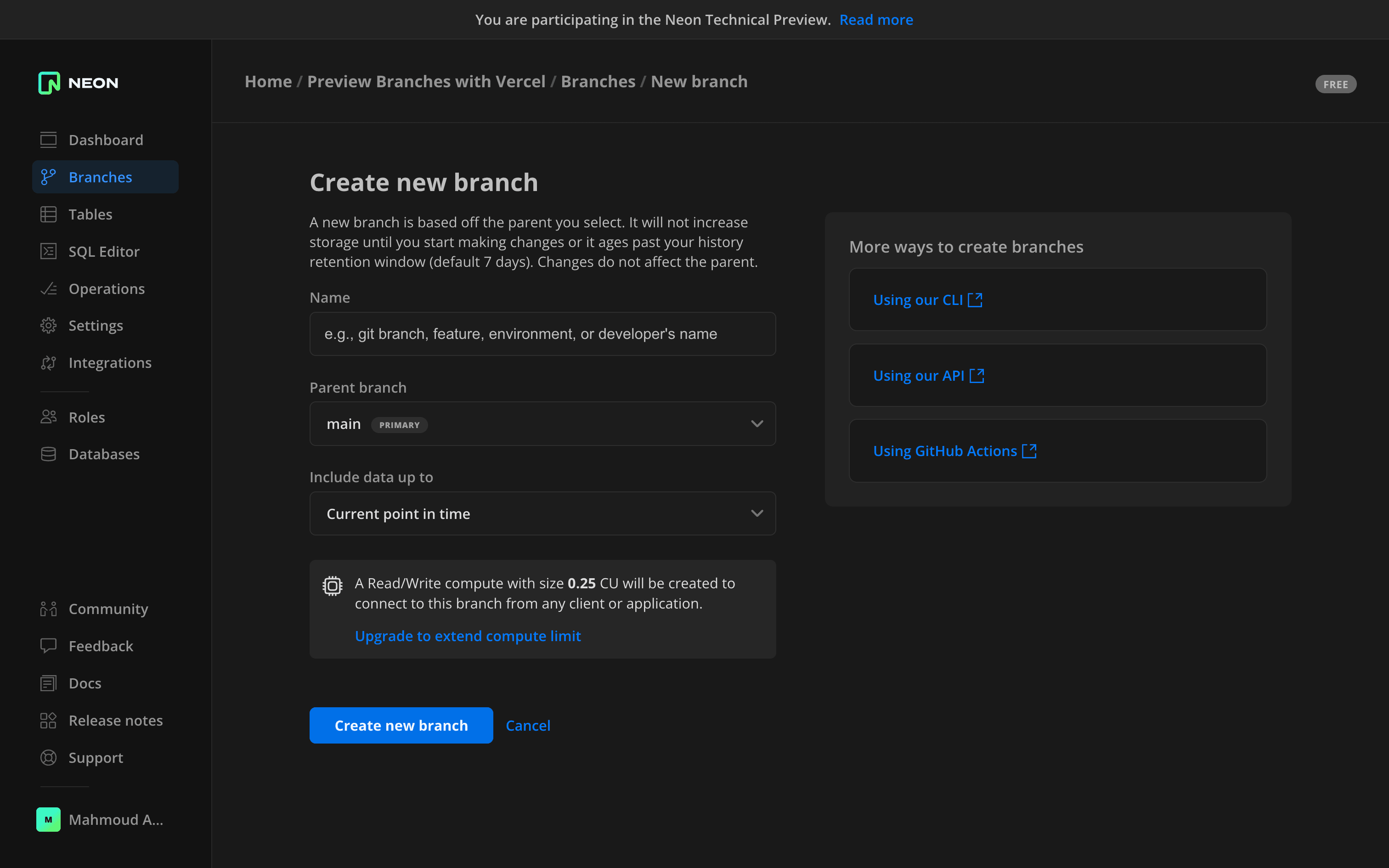
Here, you will first need to specify the parent branch that will be copied. Right now, you only have the main branch, but you can create a branch from other branches as well.
You will then need to specify the data you want to include. For that, you have several options:
- Current point in time: this will include all of the available data
- Specific date and time: this enables you to include all data up to a certain point in time. This is useful if you want to restore your branch to a previous state. You can create a branch from any previous point in time as long as it falls within your history-retention window.
- Specific Log Sequence Number: include data up to a certain LSN in the database log. This option allows for precise data recovery
Choose the main branch as the parent, pick the “Current point in time” option, and click “Create new branch”. You will get a new connection string that is different than the main branch. This connection string will be associated with the newly created branch.
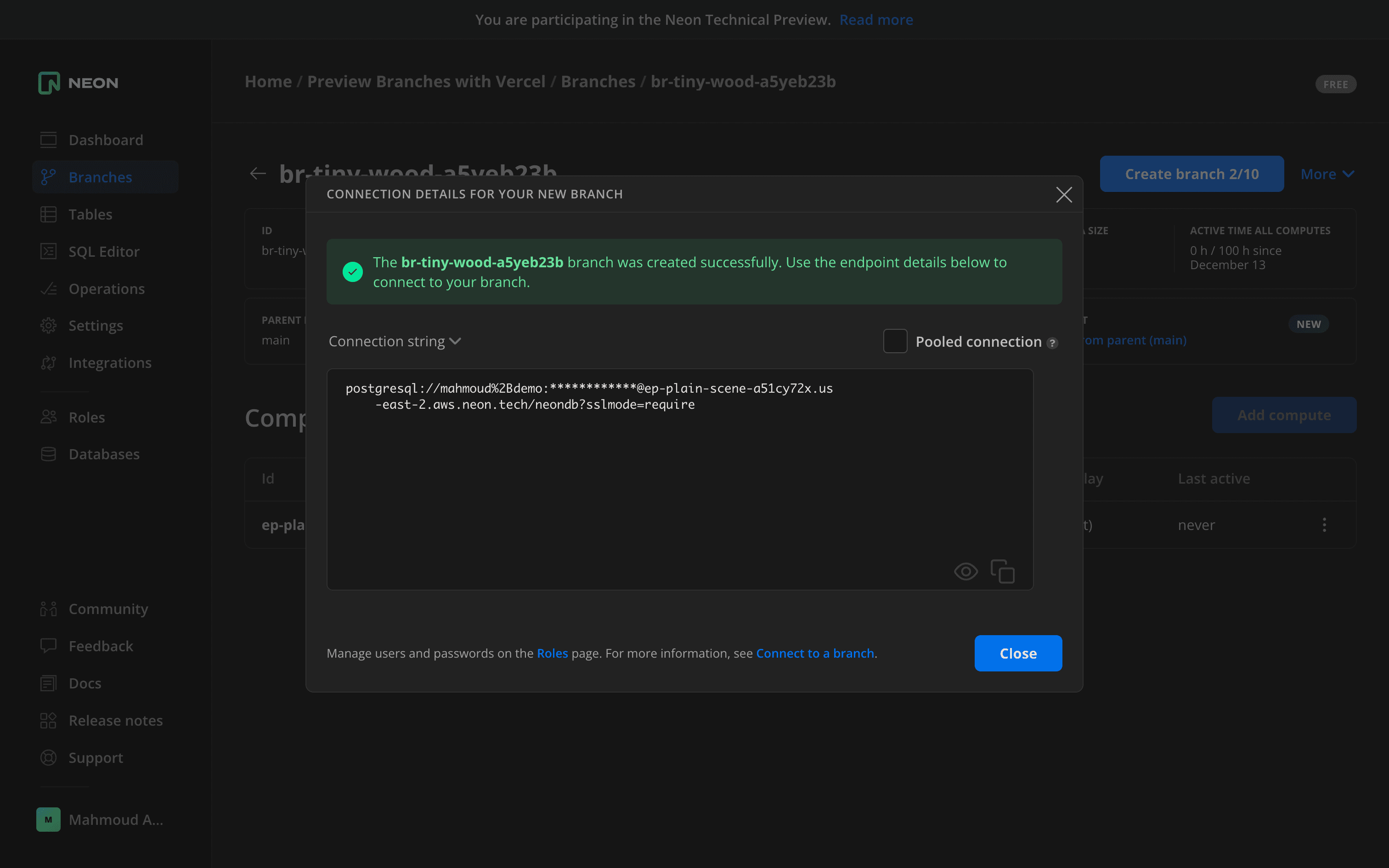
If you go to the tables page, you can select the newly created branch, and you will find that it contains all of the main branch’s data.
Now, to test that branches are isolated from one another, go back to the SQL Editor, select the newly created branch from the branch selector drop-down in the top-right of the console, and run the following query:
INSERT INTO elements VALUES ('Sodium', 11, 'Na'), ('Magnesium', 12, 'Mg'), ('Aluminum', 13, 'Al'), ('Silicon', 14, 'Si'), ('Phosphorus', 15, 'P'), ('Sulfur', 16, 'S'), ('Chlorine', 17, 'Cl'), ('Argon', 18, 'Ar'), ('Potassium', 19, 'K'), ('Calcium', 20, 'Ca');This query adds ten more items to the elements table. If you go back to the tables page, you will be able to compare the difference in data between the newly created branch and the main branch.

Creating a branch for every Preview environment
Neon offers an API that you can use to manage resources programmatically. You can use it along with a CI/CD tool to achieve the following flow:
- A developer will work on changes locally against a local Postgres instance or a Neon branch. These changes could potentially include schema changes.
- They will then open a pull request which triggers a CI/CD workflow that does the following:
- Creates a Neon branch
- Applies database migrations if there are any
- Creates a preview deployment and uses the newly created Neon branch for the database
- If everything looks good in the preview environment, the developer will merge their changes. This will trigger another CI/CD workflow that deploys the app to production. This workflow does the following:
- Applies the database migrations to the primary Neon branch
- Creates a production deployment
- Deletes the old Neon preview branch, which is no longer needed

Seeing the flow in action
Setting up the demo project locally
To see the flow in action, we created a demo app that displays the data coming from the elements table that we created previously. The app is built using Next.js, Prisma, and Neon and is deployed to Vercel.
For our CI/CD pipeline for this project, we’ll use GitHub Actions, which are automated workflows that you define as code. These workflows are written in YAML, and they live in a .github folder inside your project’s repository.
To clone the demo app locally, run the following command:
git clone https://github.com/neondatabase/preview-branches-with-vercel
cd preview-branches-with-vercel
npm installYou will then need to copy the .env.example file to a new file called .env. You can do that by running the following command:
cp .env.example .envNext, add the following environment variables which you can get from the Neon console. Add the database credentials:
DATABASE_URL = "" # the pooled connection to the database. It has a `-pooler` suffix
DIRECT_URL = "" # the direct connection string to the database
Finally, run the setup script, which creates the tables and runs a seed script:
npm run setupYou can now start a development server by running the following command:
npm run devThis command starts a development server which will run at http://localhost:3000. You should see the following UI:

A look at the GitHub actions
If you open the project in your text editor of choice, you will find that there are three files in the .github folder located at the root of your project:
cleanup-preview.yml: this workflow deletes Neon preview branches. It runs whenever a pull request is merged/closeddeploy-preview.yml: this workflow creates and deploys to a preview environment. It runs whenever a pull request is opened.deploy-production.yml: this workflow deploys the app to production. It runs whenever a commit is pushed to the main git branch.
Before diving into the code for these workflows, you must add a few secrets to your GitHub project’s repository. To do that, navigate to your repository in GitHub, and go to Settings > Security > Secrets and variables > Actions. You will then need to add the following secrets:
VERCEL_TOKEN– this is the API key for Vercel. It will be used to create preview environments (also known as Preview Deployments) and deploy the app to production. You will find it in Vercel, in Settings > Tokens > Create Token.NEON_API_KEY– this is the API key for the Neon user, which will be used to create the branches. You can find it in your Neon account under Settings > Developer settings > Generate new API key.NEON_PROJECT_ID– this is the ID of the Neon project. You can find it in the Neon console on the Settings page.DATABASE_URL– this is the pooled connection string of the production database. It will be used by your app to run queries. You can find in it in the Connection Details widget on the Neon Dashboard.DIRECT_URL– this is the direct connection string to the database. Prisma Migrate requires this to run migrations reliably. You can find it in the Connection Details widget on the Neon Dashboard.NEON_DATABASE_USERNAME– the name of the database role that will be used when creating a branch. You can obtain the user name from your Neon connection string.GH_TOKEN– this is required for commenting on pull requests
These are all of the secrets you will need. Now, here is an overview of the GitHub actions that this project uses. When you open the deploy-preview.yml file, you will see the following:
name: Deploy Preview
on: [pull_request]
env:
NEON_DATABASE_USERNAME: ${{ secrets.NEON_DATABASE_USERNAME }} # change this to your database username
GH_TOKEN: ${{ secrets.GH_TOKEN }} # Required for commenting on pull requests for private repos
NEON_API_KEY: ${{ secrets.NEON_API_KEY }} # You can generate a an API key in your account settings
NEON_PROJECT_ID: ${{ secrets.NEON_PROJECT_ID }} # You can find this in your project settings
VERCEL_TOKEN: ${{ secrets.VERCEL_TOKEN }}
jobs:
deploy-preview:
permissions: write-all
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Get branch name
id: branch-name
uses: tj-actions/branch-names@v8
- name: Create Neon Branch
id: create-branch
uses: neondatabase/create-branch-action@v4
with:
project_id: ${{ env.NEON_PROJECT_ID }}
# parent: dev # optional (defaults to your primary branch)
branch_name: preview/pr-${{ github.event.number }}-${{ steps.branch-name.outputs.current_branch }}
username: ${{ env.NEON_DATABASE_USERNAME }}
api_key: ${{ env.NEON_API_KEY }}
- name: Run Migrations
run: |
touch .env
echo DATABASE_URL=${{ steps.create-branch.outputs.db_url_with_pooler }}?sslmode=require >> .env
echo DIRECT_URL=${{ steps.create-branch.outputs.db_url }}?sslmode=require >> .env
npx prisma generate
npx prisma migrate deploy
- name: Install Vercel CLI
run: npm install --global vercel@latest
- name: Pull Vercel Environment Information
run: vercel pull --yes --environment=preview --token=${{ env.VERCEL_TOKEN }}
- name: Build Project Artifacts
run: vercel build --token=${{ env.VERCEL_TOKEN }}
- name: Deploy Preview to Vercel
id: deploy
run: echo preview_url=$(vercel deploy --prebuilt --token=${{ env.VERCEL_TOKEN }}) >> $GITHUB_OUTPUT
- name: Comment on Pull Request
uses: thollander/actions-comment-pull-request@v2
with:
# GITHUB_TOKEN: ${{ env.GH_TOKEN }}
message: |
Vercel Preview URL :rocket: : ${{ steps.deploy.outputs.preview_url }}
Neon branch :elephant: : https://console.neon.tech/app/projects/${{ env.NEON_PROJECT_ID }}/branches/${{ steps.create-branch.outputs.branch_id }}
This workflow runs every time we create a pull request by listening to the pull_request event. It checks out into the repository and gets the pull request’s git branch name to use it in the Neon branch name.
The workflow then creates a Neon branch using the official create branch action that is provided by Neon. This action takes a Neon project ID, the name of the branch, the database username, and a Neon API Key. By default, branches are created from the primary branch, however you can choose another branch as the parent.
When naming preview branches, we recommend following the naming convention preview/pr-<pull_request_number>-<git-branch-name> to identify these branches easily. Example: preview/pr-123-feat/new-login-screen.
The next step is applying database migrations. You get the newly created Neon branch’s connection string from the create branch step and then run any pending database migrations against the Neon preview branch. This example workflow uses Prisma Migrate, which is an imperative database schema migration tool. You can of course swap it out with your tool of choice.
The next step is using the Vercel CLI to build and deploy a preview that uses the Neon preview branch.
Finally, we comment on the pull request with the URL of the preview deployment, which we get from the deployment step, along with a link to the Neon console for the project branch.

It is a good idea to disable the automatic preview deployments that Vercel creates because they are now triggered using a GitHub action. To do that, you need to enable the “Ignored Build Step” field. Go to your Vercel project settings, select Git, and then add the following command:
if [ "$VERCEL_ENV" == "production" ]; then exit 1; else exit 0; fi. This command causes Vercel to skip triggering a build if it’s a preview. You can learn more in this guide.
When you open the deploy-production.yml file, you will see the following:
name: Deploy Production
on:
push:
branches:
- 'main'
env:
VERCEL_TOKEN: ${{ secrets.VERCEL_TOKEN }}
DATABASE_URL: ${{ secrets.DATABASE_URL }}
DIRECT_URL: ${{ secrets.DIRECT_URL }}
jobs:
deploy-production:
permissions: write-all
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Run Prisma Migrate
run: |
npx prisma generate
npx prisma migrate deploy
- name: Install Vercel CLI
run: npm install --global vercel@latest
- name: Pull Vercel Environment Information
run: vercel pull --yes --environment=production --token=${{ secrets.VERCEL_TOKEN }}
- name: Build Project Artifacts
run: vercel build --prod --token=${{ secrets.VERCEL_TOKEN }}
- name: Deploy Project Artifacts to Vercel
run: vercel deploy --prebuilt --prod --token=${{ secrets.VERCEL_TOKEN }}This workflow runs every time we push a commit to the main branch on GitHub by listening to the push event. Next, the workflow runs any pending database migrations against the production database. It then deploys the app to production.
Finally, if you open the cleanup-preview.yml file, you’ll see the following:
name: Clean up Preview Deployment
on:
pull_request:
types: [closed]
jobs:
delete-preview:
runs-on: ubuntu-latest
steps:
- name: Delete Neon Branch
uses: neondatabase/delete-branch-action@v3.1.3
with:
project_id: ${{ secrets.NEON_PROJECT_ID }}
branch: preview/pr-${{ github.event.number }}-${{ github.event.pull_request.head.ref }}
api_key: ${{ secrets.NEON_API_KEY }}This workflow runs when a pull request is closed, and it deletes the Neon preview branch that’s associated with the pull request using the official delete branch action. This action takes the branch name or ID.
Conclusion
In this tutorial, you learned how to provision a database for every preview environment by leveraging Neon’s branching feature along with GitHub Actions and Vercel.
You can swap out GitHub actions with another CI/CD tool or swap out Vercel with another deployment provider, as long as they support the preview environment workflow. If there are other deployment providers or CI/CD tools you would like us to cover, feel free to reach out to us in our community forum.
If you want to try out this flow on Neon, you can sign up today for free. No credit card required.